In a previous post, I dealt with the nearly-normal statistics of common things, like river crests, and explained why 100 year floods come more often than once every hundred years. As is not uncommon, the data was sort-of like a normal distribution, but deviated at the tail (the fantastic tail of the abnormal distribution). But now I’d like to present my take on a sort of statistics that (I think) should be used for the common problem of uncommon events: car crashes, fires, epidemics, wars…
Normally the mathematics used for these processes is Poisson statistics, and occasionally exponential statistics. I think these approaches lead to incorrect conclusions when applied to real-world cases of interest, e.g. choosing the size of a police force or fire department of a small town that rarely sees any crime or fire. This is relevant to Oak Park Michigan (where I live). I’ll show you how it’s treated by Poisson, and will then suggest a simpler way that’s more relevant.
First, consider an idealized version of Oak Park, Michigan (a semi-true version until the 1980s): the town had a small police department and a small fire department that saw only occasional crimes or fires, all of which required only 2 or 4 people respectively. Lets imagine that the likelihood of having one small fire at a given time is x = 5%, and that of having a violent crime is y =5% (it was 6% in 2011). A police department will need to have to have 2 policemen on call at all times, but will want 4 on the 0.25% chance that there are two simultaneous crimes (.05 x .05 = .0025); the fire department will want 8 souls on call at all times for the same reason. Either department will use the other 95% of their officers dealing with training, paperwork, investigations of less-immediate cases, care of equipment, and visiting schools, but this number on call is needed for immediate response. As there are 8760 hours per year and the police and fire workers only work 2000 hours, you’ll need at least 4.4 times this many officers. We’ll add some more for administration and sick-day relief, and predict a total staff of 20 police and 40 firemen. This is, more or less, what it was in the 1980s.
If each fire or violent crime took 3 hours (1/8 of a day), you’ll find that the entire on-call staff was busy 7.3 times per year (8x365x.0025 = 7.3), or a bit more since there is likely a seasonal effect, and since fires and violent crimes don’t fall into neat time slots. Having 3 fires or violent crimes simultaneously was very rare — and for those rare times, you could call on nearby communities, or do triage.
In response to austerity (towns always overspend in the good times, and come up short later), Oak Park realized it could use fewer employees if they combined the police and fire departments into an entity renamed “Public safety.” With 45-55 employees assigned to combined police / fire duty they’d still be able to handle the few violent crimes and fires. The sum of these events occurs 10% of the time, and we can apply the sort of statistics above to suggest that about 91% of the time there will be neither a fire nor violent crime; about 9% of the time there will be one or more fires or violent crimes (there is a 5% chance for each, but also a chance that 2 happen simultaneously). At least two events will occur 0.9% of the time (2 fires, 2 crimes or one of each), and they will have 3 or more events .09% of the time, or twice per year. The combined force allowed fewer responders since it was only rarely that 4 events happened simultaneously, and some of those were 4 crimes or 3 crimes and a fire — events that needed fewer responders. Your only real worry was when you have 3 fires, something that should happen every 3 years, or so, an acceptable risk at the time.
Before going to what caused this model of police and fire service to break down as Oak Park got bigger, I should explain Poisson statistics, exponential Statistics, and Power Law/ Fractal Statistics. The only type of statistics taught for dealing with crime like this is Poisson statistics, a type that works well when the events happen so suddenly and pass so briefly that we can claim to be interested in only how often we will see multiples of them in a period of time. The Poisson distribution formula is, P = rke-λ/r! where P is the Probability of having some number of events, r is the total number of events divided by the total number of periods, and k is the number of events we are interested in.
Using the data above for a period-time of 3 hours, we can say that r= .1, and the likelihood of zero, one, or two events begin in the 3 hour period is 90.4%, 9.04% and 0.45%. These numbers are reasonable in terms of when events happen, but they are irrelevant to the problem anyone is really interested in: what resources are needed to come to the aid of the victims. That’s the problem with Poisson statistics: it treats something that no one cares about (when the thing start), and under-predicts the important things, like how often you’ll have multiple events in-progress. For 4 events, Poisson statistics predicts it happens only .00037% of the time — true enough, but irrelevant in terms of how often multiple teams are needed out on the job. We need four teams no matter if the 4 events began in a single 3 hour period or in close succession in two adjoining periods. The events take time to deal with, and the time overlaps.
The way I’d dealt with these events, above, suggests a power law approach. In this case, each likelihood was 1/10 the previous, and the probability P = .9 x10-k . This is called power law statistics. I’ve never seen it taught, though it appears very briefly in Wikipedia. Those who like math can re-write the above relation as log10P = log10 .9 -k.
One can generalize the above so that, for example, the decay rate can be 1/8 and not 1/10 (that is the chance of having k+1 events is 1/8 that of having k events). In this case, we could say that P = 7/8 x 8-k , or more generally that log10P = log10 A –kβ. Here k is the number of teams required at any time, β is a free variable, and Α = 1-10-β because the sum of all probabilities has to equal 100%.
In college math, when behaviors like this appear, they are incorrectly translated into differential form to create “exponential statistics.” One begins by saying ∂P/∂k = -βP, where β = .9 as before, or remains some free-floating term. Everything looks fine until we integrate and set the total to 100%. We find that P = 1/λ e-kλ for k ≥ 0. This looks the same as before except that the pre-exponential always comes out wrong. In the above, the chance of having 0 events turns out to be 111%. Exponential statistics has the advantage (or disadvantage) that we find a non-zero possibility of having 1/100 of a fire, or 3.14159 crimes at a given time. We assign excessive likelihoods for fractional events and end up predicting artificially low likelihoods for the discrete events we are interested in except going away from a calculus that assumes continuity in a world where there is none. Discrete math is better than calculus here.
I now wish to generalize the power law statistics, to something similar but more robust. I’ll call my development fractal statistics (there’s already a section called fractal statistics on Wikipedia, but it’s really power-law statistics; mine will be different). Fractals were championed by Benoit B. Mandelbrot (who’s middle initial, according to the old joke, stood for Benoit B. Mandelbrot). Many random processes look fractal, e.g. the stock market. Before going here, I’d like to recall that the motivation for all this is figuring out how many people to hire for a police /fire force; we are not interested in any other irrelevant factoid, like how many calls of a certain type come in during a period of time.
To choose the size of the force, lets estimate how many times per year some number of people are needed simultaneously now that the city has bigger buildings and is seeing a few larger fires, and crimes. Lets assume that the larger fires and crimes occur only .05% of the time but might require 15 officers or more. Being prepared for even one event of this size will require expanding the force to about 80 men; 50% more than we have today, but we find that this expansion isn’t enough to cover the 0.0025% of the time when we will have two such major events simultaneously. That would require a 160 man fire-squad, and we still could not deal with two major fires and a simultaneous assault, or with a strike, or a lot of people who take sick at the same time.
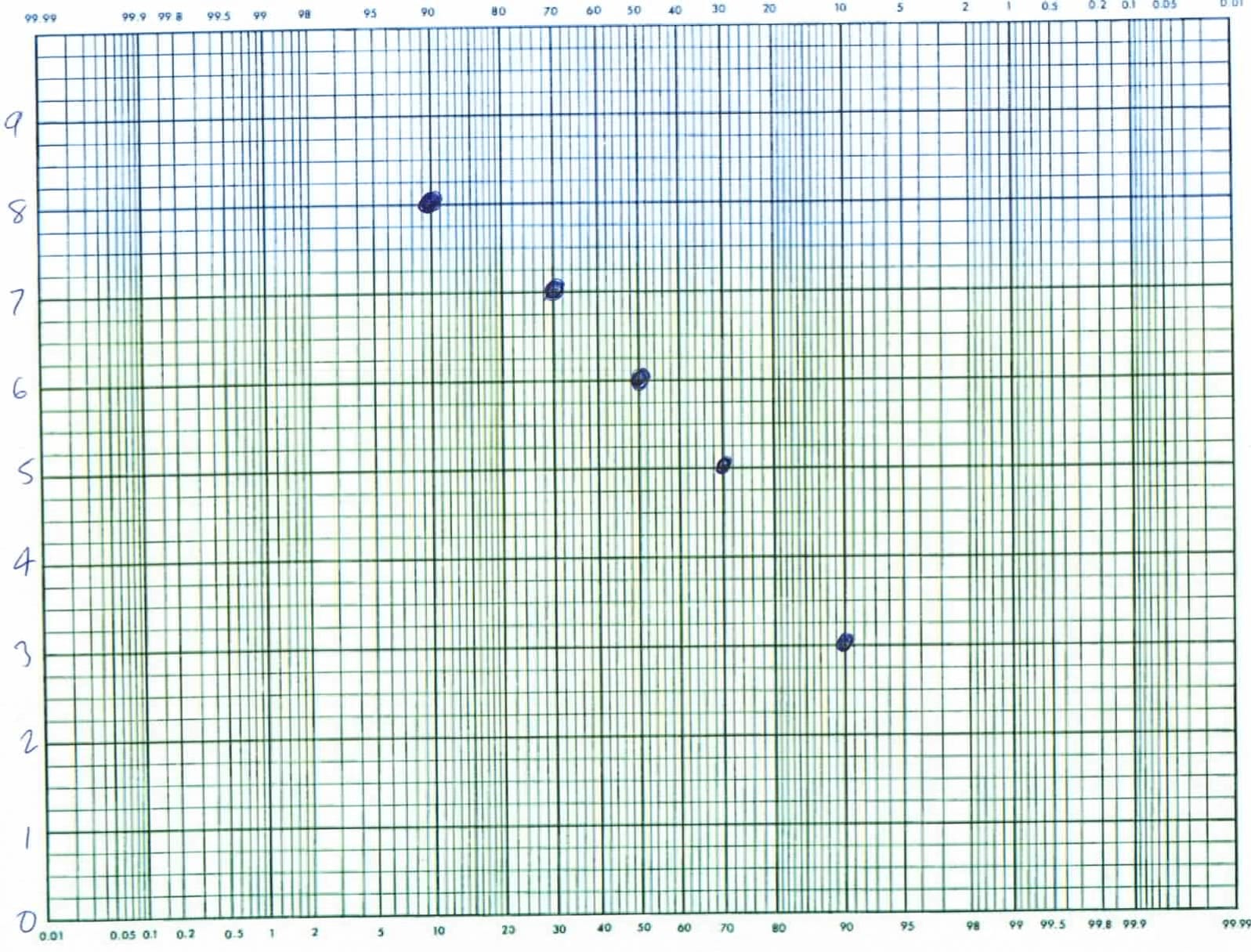
To treat this situation mathematically, we’ll say that the number times per year where a certain number of people are need, relates to the number of people based on a simple modification of the power law statistics. Thus: log10N = A – βθ where A and β are constants, N is the number of times per year that some number of officers are needed, and θ is the number of officers needed. To solve for the constants, plot the experimental values on a semi-log scale, and find the best straight line: -β is the slope and A is the intercept. If the line is really straight, you are now done, and I would say that the fractal order is 1. But from the above discussion, I don’t expect this line to be straight. Rather I expect it to curve upward at high θ: there will be a tail where you require a higher number of officers. One might be tempted to modify the above by adding a term like Cθ2 but this will cause problems at very high θ. Thus, I’d suggest a fractal fix.
My fractal modification of the equation above is the following: log10N = A-βθ-w where A and β are similar to the power law coefficients and w is the fractal order of the decay, a coefficient that I expect to be slightly less than 1. To solve for the coefficients, pick a value of w, and find the best fits for A and β as before. The right value of w is the one that results in the straightest line fit. The equation above does not look like anything I’ve seen quite, or anything like the one shown in Wikipedia under the heading of fractal statistics, but I believe it to be correct — or at least useful.
To treat this politically is more difficult than treating it mathematically. I suspect we will have to combine our police and fire department with those of surrounding towns, and this will likely require our city to revert to a pure police department and a pure fire department. We can’t expect other cities specialists to work with our generalists particularly well. It may also mean payments to other cities, plus (perhaps) standardizing salaries and staffing. This should save money for Oak Park and should provide better service as specialists tend to do their jobs better than generalists (they also tend to be safer). But the change goes against the desire (need) of our local politicians to hand out favors of money and jobs to their friends. Keeping a non-specialized force costs lives as well as money but that doesn’t mean we’re likely to change soon.
Robert E. Buxbaum December 6, 2013. My two previous posts are on how to climb a ladder safely, and on the relationship between mustaches in WWII: mustache men do things, and those with similar mustache styles get along best.