One of many best-selling books by Kenneth Deffeyes
While I was at Princeton, one of the most popular courses was geology 101 taught by Dr. Kenneth S. Deffeyes. It was a sort of “Rocks for Jocks,” but had an unusual bite since Dr. Deffeyes focussed particularly on the geology of oil. Deffeyes had an impressive understanding of oil and oil production, and one outcome of this impressive understanding was his certainty that US oil production had peaked in 1970, and that world oil was about to run out too. The prediction that US oil production had peaked was not original to him. It was called Hubbert’s peak after King Hubbert who correctly predicted (rationalized?) the date, but published it only in 1971. What Deffeyes added to Hubbard’s analysis was a simplified mathematical justification and a new prediction: that world oil production would peak in the 1980s, or 2000, and then run out fast. By 2005, the peak date was fixed to November 24, of the same year: Thanksgiving day 2005 ± 3 weeks.
As with any prediction of global doom, I was skeptical, but generally trusted the experts, and virtually every experts was on board to predict gloom in the near future. A British group, The Institute for Peak Oil picked 2007 for the oil to run out, and the several movies expanded the theme, e.g. Mad Max. I was convinced enough to direct my PhD research to nuclear fusion engineering. Fusion being presented as the essential salvation for our civilization to survive beyond 2050 years or so. I’m happy to report that the dire prediction of his mathematics did not come to pass, at least not yet. To quote Yogi Berra, “In theory, theory is just like reality.” Still I think it’s worthwhile to review the mathematical thinking for what went wrong, and see if some value might be retained from the rubble.
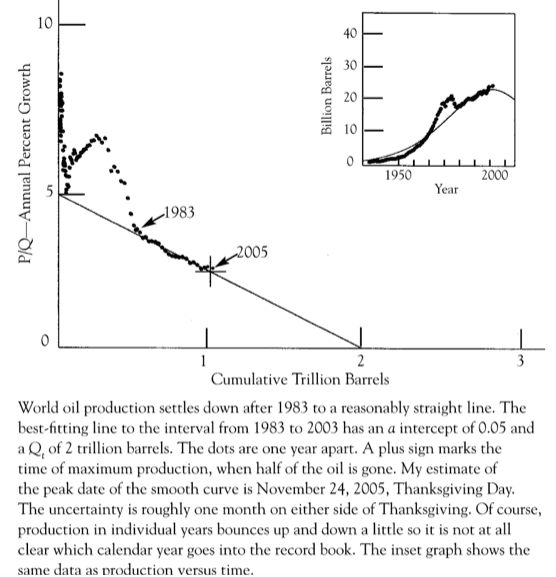 Deffeyes’s Maltheisan proof went like this: take a year-by year history of the rate of production, P and divide this by the amount of oil known to be recoverable in that year, Q. Plot this P/Q data against Q, and you find the data follows a reasonably straight line: P/Q = b-mQ. This occurs between 1962 and 1983, or between 1983 and 2005. Fro whichever straight line you pick, m and b are positive. Once you find values for m and b that you trust, you can rearrange the equation to read,
Deffeyes’s Maltheisan proof went like this: take a year-by year history of the rate of production, P and divide this by the amount of oil known to be recoverable in that year, Q. Plot this P/Q data against Q, and you find the data follows a reasonably straight line: P/Q = b-mQ. This occurs between 1962 and 1983, or between 1983 and 2005. Fro whichever straight line you pick, m and b are positive. Once you find values for m and b that you trust, you can rearrange the equation to read,
P = -mQ2+ bQ
You the calculate the peak of production from this as the point where dP/dQ = 0. With a little calculus you’ll see this occurs at Q = b/2m, or at P/Q = b/2. This is the half-way point on the P/Q vs Q line. If you extrapolate the line to zero production, P=0, you predict a total possible oil production, QT = b/m. According to this model this is always double the total Q discovered by the peak. In 1983, QT was calculated to be 1 trillion barrels. By May of 2005, again predicted to be a peak year, QT had grown to two trillion barrels.
I suppose Deffayes might have suspected there was a mistake somewhere in the calculation from the way that QT had doubled, but he did not. See him lecture here in May 2005; he predicts war, famine, and pestilence, with no real chance of salvation. It’s a depressing conclusion, confidently presented by someone enamored of his own theories. In retrospect, I’d say he did not realize that he was over-enamored of his own theory, and blind to the possibility that the P/Q vs Q line might curve upward, have a positive second derivative.
Aside from his theory of peak oil, Deffayes also had a theory of oil price, one that was not all that popular. It’s not presented in the YouTube video, nor in his popular books, but it’s one that I still find valuable, and plausibly true. Deffeyes claimed the wildly varying prices of the time were the result of an inherent quay imbalance between a varying supply and an inelastic demand. If this was the cause, we’d expect the price jumps of oil up and down will match the way the wait-line at a barber shop gets longer and shorter. Assume supply varies because discoveries came in random packets, while demand rises steadily, and it all makes sense. After each new discovery, price is seen to fall. It then rises slowly till the next discovery. Price is seen as a symptom of supply unpredictability rather than a useful corrective to supply needs. This view is the opposite of Adam Smith, but I think he’s not wrong, at least in the short term with a necessary commodity like oil.
Academics accepted the peak oil prediction, I suspect, in part because it supported a Marxian remedy. If oil was running out and the market was broken, then our only recourse was government management of energy production and use. By the late 70s, Jimmy Carter told us to turn our thermostats to 65. This went with price controls, gas rationing, and a 55 mph speed limit, and a strong message of population management – birth control. We were running out of energy, we were told because we had too many people and they (we) were using too much. America’s grown days were behind us, and only the best and the brightest could be trusted to manage our decline into the abyss. I half believed these scary predictions, in part because everyone did, and in part because they made my research at Princeton particularly important. The Science fiction of the day told tales of bold energy leaders, and I was ready to step up and lead, or so I thought.
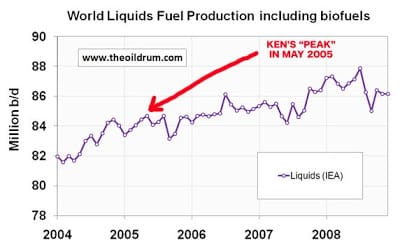
By 2009 Dr. Deffayes was being regarded as chicken little as world oil production continued to expand.
I’m happy to report that none of the dire predictions of the 70’s to 90s came to pass. Some of my colleagues became world leaders, the rest because stock brokers with their own private planes and SUVs. As of my writing in 2018, world oil production has been rising, and even King Hubbert’s original prediction of US production has been overturned. Deffayes’s reputation suffered for a few years, then politicians moved on to other dire dangers that require world-class management. Among the major dangers of today, school shootings, Ebola, and Al Gore’s claim that the ice caps will melt by 2014, flooding New York. Sooner or later, one of these predictions will come true, but the lesson I take is that it’s hard to predict change accurately.
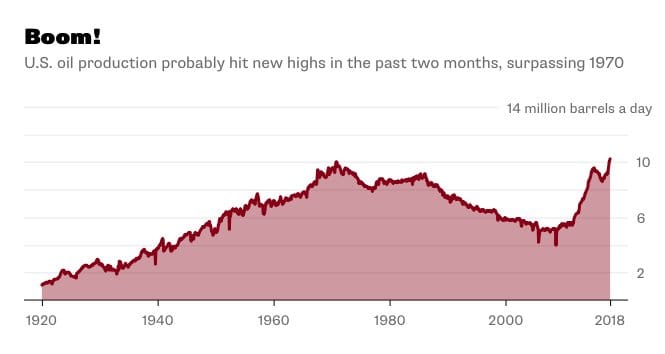
Just when you thought US oil was depleted, production began rising. We now produce more than in 1970.
Much of the new oil production you’ll see on the chart above comes from tar-sands, oil the Deffeyes considered unrecoverable, even while it was being recovered. We also discovered new ways to extract leftover oil, and got better at using nuclear electricity and natural gas. In the long run, I expect nuclear electricity and hydrogen will replace oil. Trees have a value, as does solar. As for nuclear fusion, it has not turned out practical. See my analysis of why.
Robert Buxbaum, March 15, 2018. Happy Ides of March, a most republican holiday.

 Parallel lines have so much in common.
Parallel lines have so much in common.