There are two main obstacles students have to overcome to learn statistics: one mathematical one philosophical. The math is somewhat difficult, and will be new to a high schooler. What’s more, philosophically, it is rarely obvious what it means to discover a true pattern, or underlying cause. Nor is it obvious how to separate the general pattern from the random accident, the pattern from the variation. This philosophical confusion (cause and effect, essence and accident) is exists in the back of even in the greatest minds. Accepting and dealing with it is at the heart of the best research: seeing what is and is not captured in the formulas of the day. But it is a lot to ask of the young (or the old) who are trying to understand the statistical technique while at the same time trying to understand the subject of the statistical analysis, For young students, especially the good ones, the issue of general and specific will compound the difficulty of the experiment and of the math. Thus, I’ll try to teach statistics with a problem or two where the distinction between essential cause and random variation is uncommonly clear.
A good case to get around the philosophical issue is gambling with crooked dice. I show the class a pair of normal-looking dice and a caliper and demonstrate that the dice are not square; virtually every store-bought die is not square, so finding an uneven pair is easy. After checking my caliper, students will readily accept that these dice are crooked, and so someone who knows how it is crooked will have an unfair advantage. After enough throws, someone who knows the degree of crookedness will win more often than those who do not. Students will also accept that there is a degree of randomness in the throw, so that any pair of dice will look pretty fair if you don’t gable with them too long. I can then use statistics to see which faces show up most, and justify the whole study of statistics to deal with a world where the dice are loaded by God, and you don’t have a caliper, or any more-direct way of checking them. The underlying uneven-ness of the dice is the underlying pattern, the random part in this case is in the throw, and you want to use statistics to grasp them both.
Two important numbers to understand when trying to use statistics are the average and the standard deviation. For an honest pair of dice, you’d expect an average of 1/6 = 0.1667 for every number on the face. But throw a die a thousand times and you’ll find that hardly any of the faces show up at the average rate of 1/6. The average of all the averages will still be 1/6. We will call that grand average, 1/6 = x°-bar, and we will call the specific face average of the face Xi-bar. where i is one, two three, four, five, or six.
There is also a standard deviation — SD. This relates to how often do you expect one fact to turn up more than the next. SD = √SD2, and SD2 is defined by the following formula
SD2 = 1/n ∑(xi – x°-bar)2
Let’s pick some face of the dice, 3 say. I’ll give a value of 1 if we throw that number and 0 if we do not. For an honest pair of dice, x°-bar = 1/6, that is to say, 1 out of 6 throws will be land on the number 3, going us a value of 1, and the others won’t. In this situation, SD2 = 1/n ∑(xi – x°-bar)2 will equal 1/6 ( (1/6)2 + 5 (5/6)2 )= 1/6 (126/36) = 3.5/6 = .58333. Taking the square root, SD = 0.734. We now calculate the standard error. For honest dice, you expect that for every face, on average
SE = Xi-bar minus x°-bar = ± SD √(1/n).
By the time you’ve thrown 10,000 throws, √(1/n) = 1/100 and you expect an error on the order of 0.0073. This is to say that you expect to see each face show up between about 0.1740 and 0.1594. In point of fact, you will likely find that at least one face of your dice shows up a lot more often than this, or a lot less often. To the extent you see that, this is the extent that your dice is crooked. If you throw someone’s dice enough, you can find out how crooked they are, and you can then use this information to beat the house. That, more or less is the purpose of science, by the way: you want to beat the house — you want to live a life where you do better than you would by random chance.
As a less-mathematical way to look at the same thing — understanding statistics — I suggest we consider a crooked coin throw with only two outcomes, heads and tails. Not that I have a crooked coin, but your job as before is to figure out if the coin is crooked, and if so how crooked. This problem also appears in political polling before a major election: how do you figure out who will win between Mr Head and Ms Tail from a sampling of only a few voters. For an honest coin or an even election, on each throw, there is a 50-50 chance of head, or of Mr Head. If you do it twice, there is a 25% chance of two heads, a 25% chance of throwing two tails and a 50% chance of one of each. That’s because there are four possibilities and two ways of getting a Head and a Tail.

Pascal’s triangle
You can systematize this with a Pascal’s triangle, shown at left. Pascal’s triangle shows the various outcomes for a coin toss, and shows the ways they can be arrived at. Thus, for example, we see that, by the time you’ve thrown the coin 6 times, or polled 6 people, you’ve introduced 26 = 64 distinct outcomes, of which 20 (about 1/3) are the expected, even result: 3 heads and 3 tails. There is only 1 way to get all heads and one way to get all tails. While an honest coin is unlikely to come up all heads or tails after six throws, more often than not an honest coin will not come up with half heads. In the case above, 44 out of 64 possible outcomes describe situations with more heads than tales, or more tales than heads — with an honest coin.
Similarly, in a poll of an even election, the result will not likely come up even. This is something that confuses many political savants. The lack of an even result after relatively few throws (or phone calls) should not be used to convince us that the die is crooked, or the election has a clear winner. On the other hand there is only a 1/32 chance of getting all heads or all tails (2/64). If you call 6 people, and all claim to be for Mr Head, it is likely that Mr Head is the true favorite to a confidence of 3% = 1/32. In sports, it’s not uncommon for one side to win 6 out of 6 times. If that happens, it is a good possibility that there is a real underlying cause, e.g. that one team is really better than the other.
And now we get to how significant is significant. If you threw 4 heads and 2 tails out of 6 throws we can accept that this is not significant because there are 15 ways to get this outcome (or 30 if you also include 2 heads and 4 tail) and only 20 to get the even outcome of 3-3. But what about if you threw 5 heads and one tail? In that case the ratio is 6/20 and the odds of this being significant is better, similarly, if you called potential voters and found 5 Head supporters and 1 for Tail. What do you do? I would like to suggest you take the ratio as 12/20 — the ratio of both ways to get to this outcome to that of the greatest probability. Since 12/20 = 60%, you could say there is a 60% chance that this result is random, and a 40% chance of significance. What statisticians call this is “suggestive” at slightly over 1 standard deviation. A standard deviation, also known as σ (sigma) is a minimal standard of significance, it’s if the one tailed value is 1/2 of the most likely value. In this case, where 6 tosses come in as 5 and 1, we find the ratio to be 6/20. Since 6/20 is less than 1/2, we meet this, very minimal standard for “suggestive.” A more normative standard is when the value is 5%. Clearly 6/20 does not meet that standard, but 1/20 does; for you to conclude that the dice is likely fixed after only 6 throws, all 6 have to come up heads or tails.

From xkcd. It’s typical in science to say that <5% chances, p< .05. If things don’t quite come out that way, you redo.
If you graph the possibilities from a large Poisson Triangle they will resemble a bell curve; in many real cases (not all) your experiential data variation will also resemble this bell curve. From a larger Poisson’s triange, or a large bell curve, you will find that the 5% value occurs at about σ =2, that is at about twice the distance from the average as to where σ = 1. Generally speaking, the number of observations you need is proportional to the square of the difference you are looking for. Thus, if you think there is a one-headed coin in use, it will only take 6 or seven observations; if you think the die is loaded by 10% it will take some 600 throws of that side to show it.
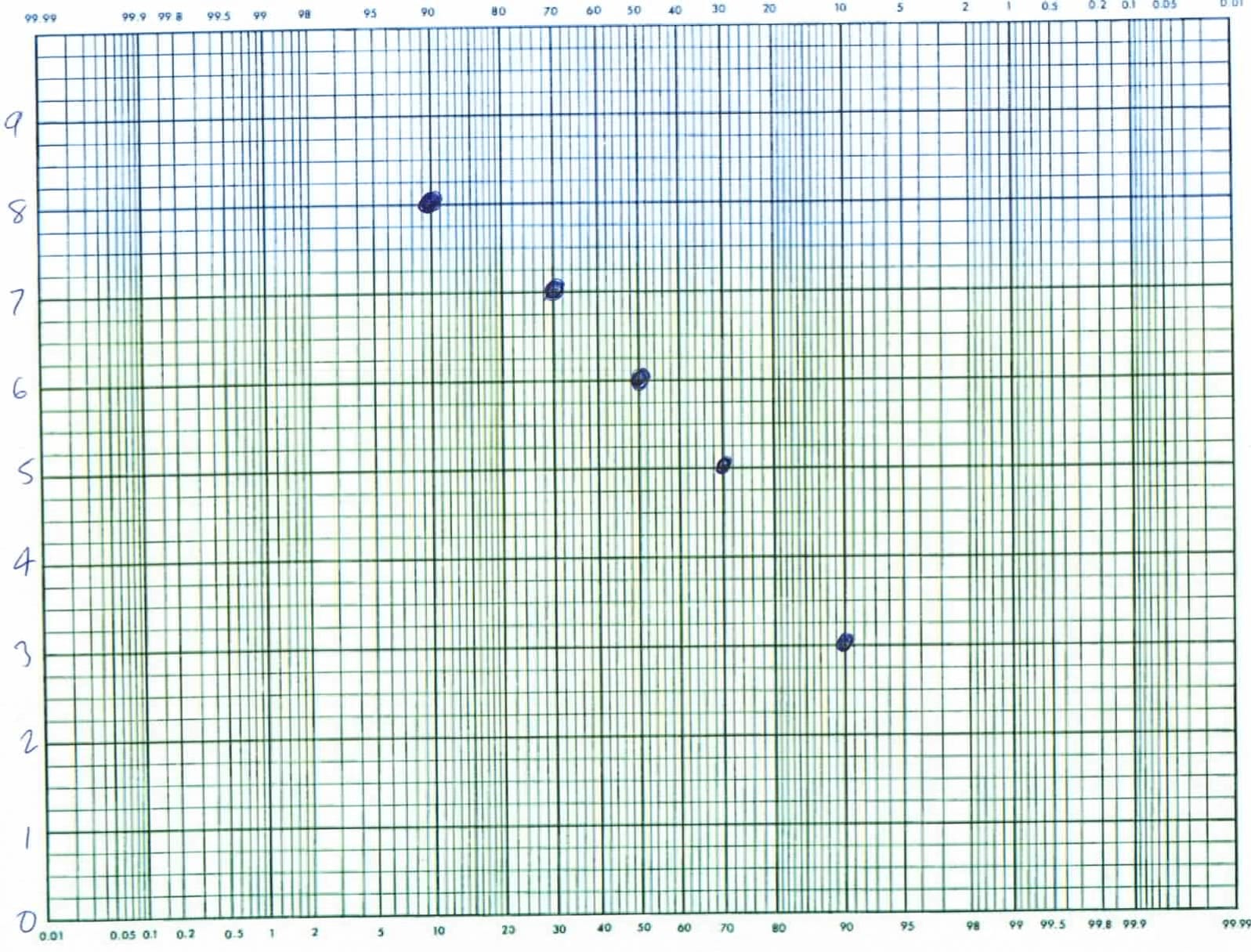
In many (most) experiments, you can not easily use the poisson triangle to get sigma, σ. Thus, for example, if you want to see if 8th graders are taller than 7th graders, you might measure the height of people in both classes and take an average of all the heights but you might wonder what sigma is so you can tell if the difference is significant, or just random variation. The classic mathematical approach is to calculate sigma as the square root of the average of the square of the difference of the data from the average. Thus if the average is <h> = ∑h/N where h is the height of a student and N is the number of students, we can say that σ = √ (∑ (<h> – h)2/N). This formula is found in most books. Significance is either specified as 2 sigma, or some close variation. As convenient as this is, my preference is for this graphical version. It also show if the data is normal — an important consideration.
If you find the data is not normal, you may decide to break the data into sub-groups. E.g. if you look at heights of 7th and 8th graders and you find a lack of normal distribution, you may find you’re better off looking at the heights of the girls and boys separately. You can then compare those two subgroups to see if, perhaps, only the boys are still growing, or only the girls. One should not pick a hypothesis and then test it but collect the data first and let the data determine the analysis. This was the method of Sherlock Homes — a very worthwhile read.
Another good trick for statistics is to use a linear regression, If you are trying to show that music helps to improve concentration, try to see if more music improves it more, You want to find a linear relationship, or at lest a plausible curve relationship. Generally there is a relationship if (y – <y>)/(x-<x>) is 0.9 or so. A discredited study where the author did not use regressions, but should have, and did not report sub-groups, but should have, involved cancer and genetically modified foods. The author found cancer increased with one sub-group, and publicized that finding, but didn’t mention that cancer didn’t increase in nearby sub-groups of different doses, and decreased in a nearby sub-group. By not including the subgroups, and not doing a regression, the author mislead people for 2 years– perhaps out of a misguided attempt to help. Don’t do that.
Dr. Robert E. Buxbaum, June 5-7, 2015. Lack of trust in statistics, or of understanding of statistical formulas should not be taken as a sign of stupidity, or a symptom of ADHD. A fine book on the misuse of statistics and its pitfalls is called “How to Lie with Statistics.” Most of the examples come from advertising.